
目前,自然语言处理中,有三种特征处理器:卷积神经网络、递归神经网络和后起之秀 Transformer。Transformer 风头已经盖过两个前辈,它抛弃了传统的卷积神经网络和递归神经网络,整个网络结构完全是由注意力机制组成。准确地讲,Transformer 仅由自注意力和前馈神经网络组成。那么,Transformer 在自然语言处理中,是如何工作的?
概 述
自然语言处理中的 Transformer 模型真正改变了我们处理文本数据的方式。
Transformer 是最近自然语言处理发展的幕后推手,包括 Google 的 BERT。
了解 Transformer 的工作原理、它如何与语言建模、序列到序列建模相关,以及它如何支持 Google 的 BERT 模型。
引 言
现在,我喜欢做一名数据科学家,从事自然语言处理(Natural Language Processing,NLP) 方面的工作。这些突破和发展正以前所未有的速度发生。从超高效的 ULMFiT 框架到 Google 的 BERT,自然语言处理真的处于一个黄金时代。
这场革命的核心是 Transformer 的概念。它改变了我们数据科学家处理文本数据的方式,你很快就会在本文中理解这一点。
想看一个 Transformer 是多么有用的例子么?请看下面的段落:

标注高亮的单词指的是同一个人:Griezmann,一名受欢迎的足球运动员。对我们而言,要弄清楚文本中这些词之间的关系并不难。但对一台机器来说,这可就是一项相当艰巨的任务了。
对机器理解自然语言来说,掌握句子中这些关系和单词序列至关重要。这就是 Transformer 概念发挥主要作用之处。
注:本文假设读者对一些深度学习概念有基本的了解。
《深度学习要领:带注意力的序列到序列建模》(Essentials of Deep Learning – Sequence to Sequence modeling with Attention)
《深度学习基础:递归神经网络导论》(Fundamentals of Deep Learning – Introduction to Recurrent Neural Networks)
《Python 中使用深度学习的文本摘要综合指南》(Comprehensive Guide to Text Summarization using Deep Learning in Python)
序列到序列模型:背景
自然语言处理中的序列到序列模型(seq2seq, Sequence-To-Sequence)用于将A型序列转换为B型序列.例如, 将英语句子翻译成德语句子就是一个序列到序列的任务
自2014年推出以来, 基于递归神经网络的序列到序列模型得到了很多人的关注.目前世界上的大多数数据都是以序列的形式存在的, 它可以是数字序列, 文本序列, 视频帧序列或音频序列
2015年增加了注意力机制, 进一步提高了这些seq2seq模型的性能。
用途
机器翻译
文本摘要
语音识别
问答系统等等
基于递归神经网络的序列到序列模型
以一个简单的序列到序列模型为例:
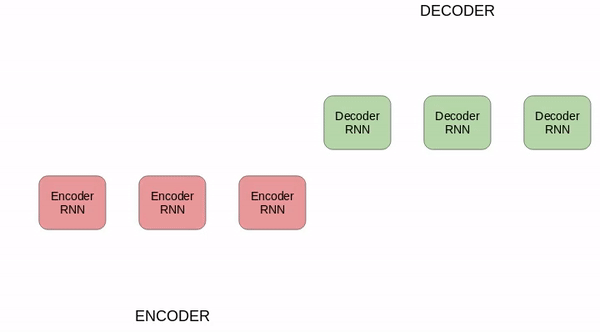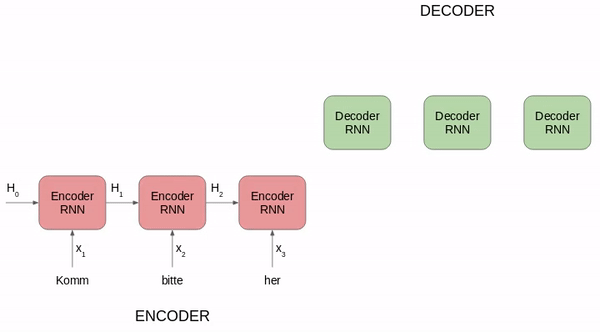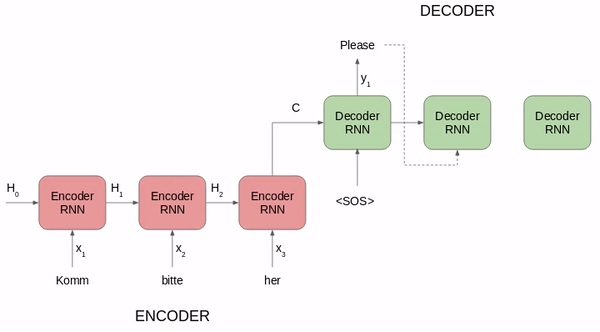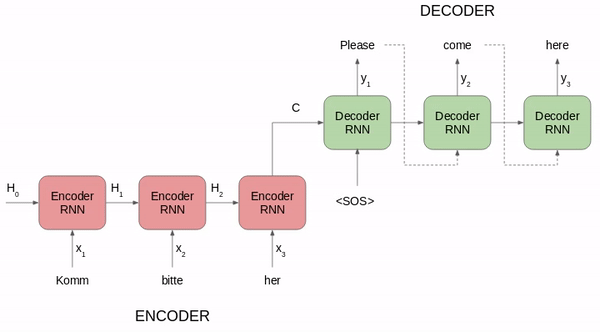
使用seq2seq进行德语到英语的翻译
分解一下上图:
编码器和解码器都是递归神经网络
在编码器中的每个时间步骤, 递归神经网络从输入序列获取词向量(xi), 从前一个时间步骤中获取一个隐藏状态(Hi)
隐藏状态在每个时间步骤中更新
最后一个单元的隐藏状态为语境矢量(context vector),它包括有关输入序列的信息
然后将该语境矢量传递给解码器, 然后使用它生产目标序列(英文短语)
如果我们使用注意力机制, 则隐状态的甲醛和将作为语境矢量传递给解码器
挑战
尽管seq2seq非常出色,但也存在一定局限性:
处理长期依赖仍然是一个挑战
模型架构的顺序特性阻止了并行化。这些挑战都是通过Google Brain的Transformer概念得到解决的
Transformer简介
自然语言处理中的Transformer是一种新颖的架构, 旨在解决序列到序列的任务, 同时轻松处理长期依赖问题。Transformer首次由论文《Attention Is All You Need》。对自然语言处理感兴趣的人都可以阅读这篇论文。
以下是论文引用:
Transformer是第一个完全依赖自注意力来计算输入和输出的表示,而不使用序列对其的递归神经网络或卷积神经网络的转换模型。
自注意力机制
把「自注意力机制」(Self-Attention)拆开来说,其实就是一句话:
让每个词在做表示时,先扫一遍整句话,找出“跟我有关”的词,然后把这些相关信息加权汇总,形成新的我。
下面分 4 步把它说透,并配 3 个具体例子,最后给一个 10 行级别的小代码(PyTorch),你可以直接跑。
1. 三张核心图:Query / Key / Value
每个输入向量 xᵢ 先线性映射成 3 个新向量:
Query qᵢ:我长什么样?
Key kⱼ:我能被谁检索?
Value vⱼ:我真正携带的信息是什么?
• 用「q 打 k」算相关性:
scoreᵢⱼ = qᵢ · kⱼ / √d 再 softmax → 权重 αᵢⱼ(所有 j 的和为 1)。
• 用 αᵢⱼ 加权求和 vⱼ,得到自注意力输出 zᵢ。
2. 一个最小故事:「The cat sat on the mat」
句子里的「sat」想知道「谁坐?」
q_sat 与 k_the、k_cat、k_on 等做点积,发现 k_cat 分数最高(α 最大)。
于是 z_sat 会携带大量「cat」的信息,表示为 “sat(cat)” 而不仅是 “sat”。
3. 三个更具体的例子
例 1:指代消解
「小明把书包忘在教室,它很沉。」
模型计算「它」的自注意力时,对「书包」的权重远高于「教室」,于是正确指代。
例 2:多义词消歧
「Apple released a new phone.」
「Apple」的 q 与「phone」的 k 分数高 → 模型知道这是“苹果公司”而非“水果”。
例 3:长距离依赖
「The keys to the cabinet that John inherited from his grandmother are missing.」
动词「are」需要跟主语「keys」匹配,但它们隔着一大串修饰语。
自注意力不依赖距离,直接给「keys」打高分,语法一致性检查一步到位。
4. 多头 & 并行:像一支乐队
把 Q/K/V 拆成 h 个头(常见 8/12/16),每个头学一种关系:
头 1 关注语法主谓关系
头 2 关注指代关系
…
最后再拼接所有头,得到更丰富的表示。
5. 10 行可运行小代码
import torch, torch.nn.functional as F
x = torch.randn(5, 64) # 5 个词,每个 64 维
Wq = torch.nn.Linear(64, 64, bias=False)
Wk = torch.nn.Linear(64, 64, bias=False)
Wv = torch.nn.Linear(64, 64, bias=False)
Q, K, V = Wq(x), Wk(x), Wv(x)
scores = Q @ K.T / 8.0 # √d=8
weights = F.softmax(scores, dim=-1)
out = weights @ V # 自注意力结果 [5, 64]
print(out.shape) # torch.Size([5, 64])跑通后把 x 换成真实词向量即可看到权重矩阵。
-------------------------------------------------
一句话总结
「自注意力 = 每个词开天眼,一句话里谁重要就多看谁一眼,然后把它们的信息加权打包带走。」
理解Transformer模型架构
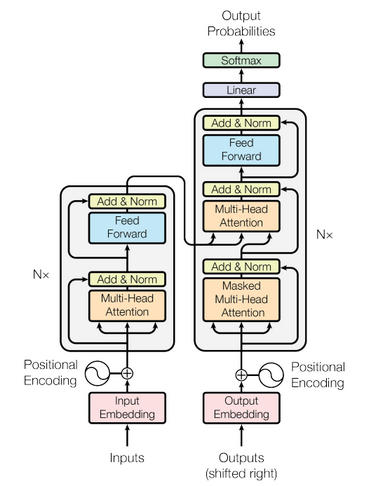
上图是Transformer架构的图例。首先我们们只关注编码器和解码器部分。
现在, 让我们观察下图。编码器块有一层多头注意力(Multi-Head Attention),然后是另一层前馈神经网络(Feed Forward Neural network)。另一方面,解码器有一个额外的掩码多头注意力(Masked Multi-Head Attention)。
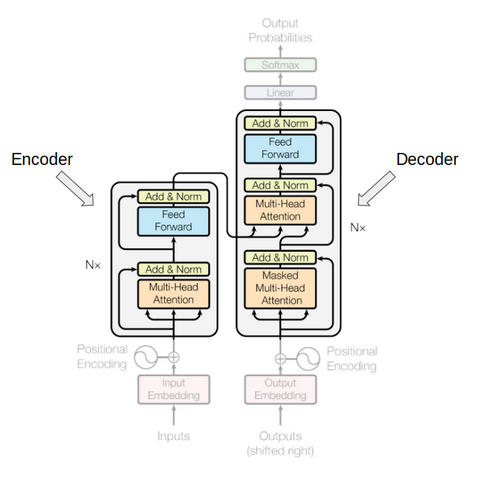
编码器和解码器块实际上是相互堆叠在一起的多个相同的编码器和解码器。编码器堆栈和解码器堆栈都具有相同数量的单元。
编码器和解码器单元的数量是一个超参数。在本文中, 我们用了6个编码器和解码器
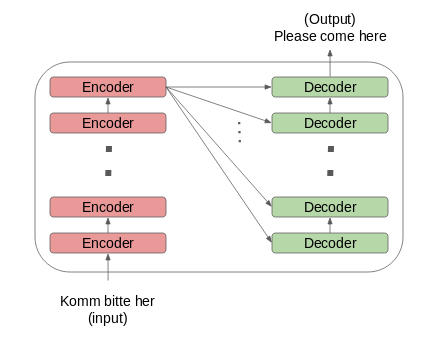
让我们看看编码器和解码器堆栈的设置是如何工作的:
将输入序列的词嵌入(word embeddings)传递给第一个编码器
然后将它们进行转换并传播到下一个编码器。
编码器堆栈中最后一个编码器的输出将传递给解码器堆栈中所有的解码器:
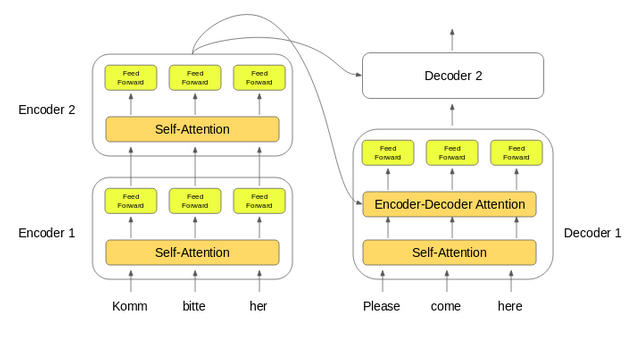
这里需要注意的一点是, 除了自注意力和前馈层外, 解码器还有一层解码器-解码器注意力层。这有助于解码器将注意力集中在输入序列的适当部分上。
你可能会想,这个“自注意力”层在Transformer中到底做了什么?
掌握自注意力的技巧
根据这篇论文所述:
自注意力,又是也称为内部注意力(intra-attention),是一种注意力机制,它将一个序列的不同位置联系起来,以计算出序列的表现形式。

请看上图, 你能弄明白这句话中的“it”指代什么嘛?
它指的是 street 还是 animal?这对我们来说是一个简单的问题,但对算法来说可不是这样的。当模型处理到“it”这个单词时,自注意力试图将“it”与同一句话中的“animal”联系起来。
自注意力允许模型查看输入序列中的其他单词,以便更好地理解序列中的某个单词。现在,让我们看看如何计算自注意力。
自注意力的计算
为便于理解,我将这一部分分为不同的步骤。
首先,我们需要从每个编码器的输入向量中创建三个向量:
查询向量
键向量
值向量
在训练过程中对这些向量进行训练和更新。完成本节之后,我们将进一步了解它们的角色。
接下来,我们将计算输入序列中每个单词的自注意力。
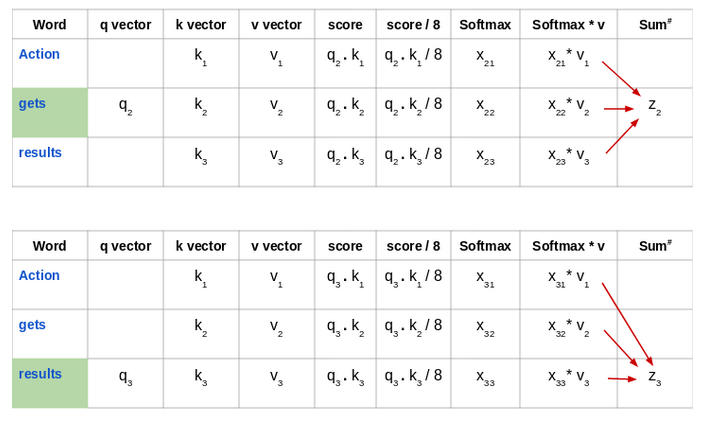
来看看这句话:“Action gets results”。为了计算第一个单词“Action”的自注意力,我们将计算短语中与“Action”相关的所有单词的得分。当我们在输入序列中编码某个单词时,该得分确定其他单词的重要性。
通过将查询向量(q1)的与所有单词的键向量(k1,k2,k3) 的点积来计算第一个单词的得分:
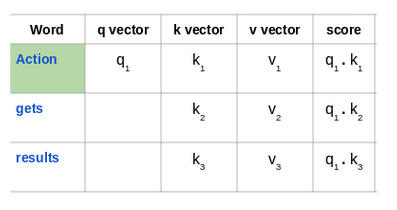
然后, 将这些得分除以8, 也就是键向量维数的平方根
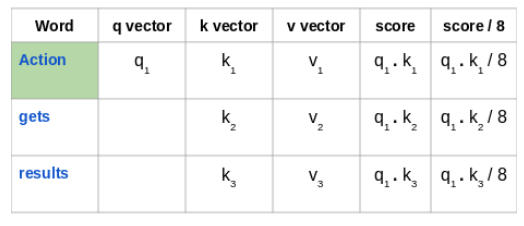
接下来,使用 softmax 激活函数对这些得分进行归一化:
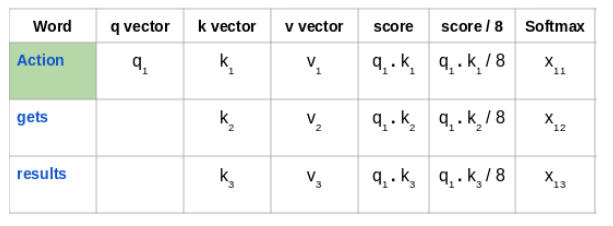
然后将这些经过归一化的得分乘以值向量(v1,v2,v3),并将得到的向量求和,得到最终向量(z1)。这是自注意力层的输出。然后将其作为输入传递给前馈网络:
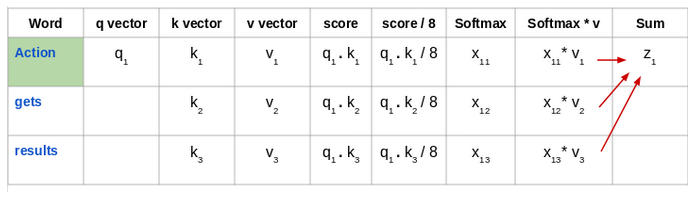
因此,z1 是输入序列“Action gets results”的第一个单词的自注意力向量。我们可以用同样的方式得到输入序列中其余单词的向量:
在 Transformer 的架构中,自注意力并不是计算一次,而是进行多次计算,并且是并行且独立进行的。因此,它被称为多头注意力。输出经过串联并进行线性转换,如下图所示。
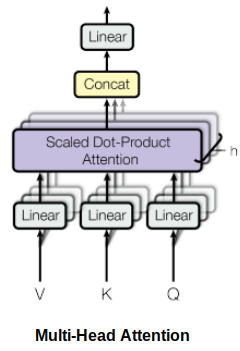
根据论文 Attention Is All You Need:
“多头注意力允许模型共同注意来自不同位置的不同表示子空间的信息。”
你可以查阅实现 Transformer 的代码:https://paperswithcode.com/paper/attention-is-all-you-need
Transformer 的局限性
Transformer 无疑是对基于递归神经网络的 seq2seq 模型的巨大改进。但它也有自身的局限性:
注意力只能处理固定长度的文本字符串。在输入系统之前,文本必须被分割成一定数量的段或块。
这种文本块会导致上下文碎片化。例如,如果一个句子从中间分隔,那么大量的上下文就会丢失。换言之,在不考虑句子或任何其他语义边界的情况下对文本进行分隔。
那么,我们如何处理这些非常重要的问题呢?这就是使用过 Transformer 的人们提出的问题。由此催生了 Transformer-XL。
理解 Transformer-XL
Transformer 架构可以学习长期依赖。但是,由于使用固定长度的上下文(输入文本段),它们无法扩展到特定的级别。为了克服这一缺点,这篇论文提出了一种新的架构:《Transformer-XL:超出固定长度上下文的注意力语言模型》(Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context)
在这种架构中,在先前段中获得的隐状态被重用为当前段的信息员。它支持对长期依赖建模,因为信息可以从一个段流向下一个段。
使用 Transformer 进行语言建模
“将语言建模看作是一个过程,在给定前面单词的情况下,估计下一个单词的概率。”
Al-Rfou 等人在 2018 年提出了将 Transformer 模型应用于语言建模的想法。根据这篇论文的观点,整个语料库可以被分割成规模可控的固定长度的段。然后,我们对 Transformer 模型进行分段独立训练,忽略了来自先前段的所有上下文信息:
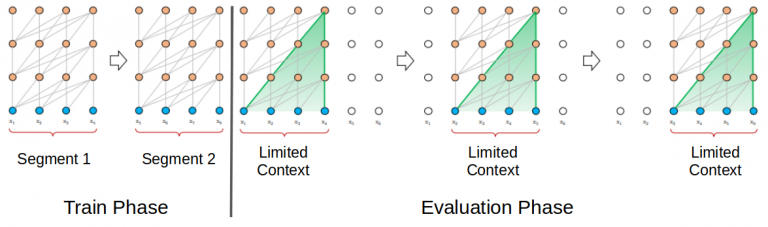
段长度为 4 的 Transformer 模型。(来源:Source: https://arxiv.org/abs/1901.02860)
这种架构不存在梯度消失的问题。但上下文的碎片化限制了它的长期依赖学习。在评估阶段,该段仅向右移动一个位置。新段必须完全从头开始处理。然而不行的是,这种评估方法非常耗费计算量。
使用 Transformer-XL 进行语言建模
在 Transformer-XL 的训练阶段,为前一个状态计算的隐状态被用作当前段的附加上下文。Transformer-XL 的这种递归机制解决了使用固定长度上下文的局限性。
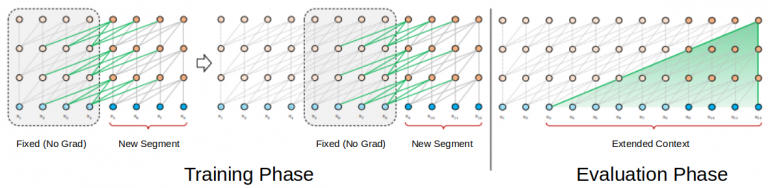
具有段长度的 Transformer-XL 模型。
在评估阶段,可以重复使用来自先前段的表示,而不是从头开始计算(就像 Transformer 模型的情况一样)。当然,这也会增加计算速度。
你可以查看实现 Transformer-XL 的代码:https://paperswithcode.com/paper/transformer-xl-attentive-language-models
自然语言处理的新感觉:Google 的 BERT
BERT,是来自来自 Transformer 的双向编码器表示(Bidirectional Encoder Representations from Transformers)的缩写。
我们都知道迁移学习在计算机视觉领域的重要性有多高。例如,深度学习预训练模型可以针对 ImageNet 数据集上的新任务进行微调,并且在相对较小的标记数据集上提供不错的结果。
类似地,预训练语言模型对于改进许多自然语言处理任务非常有效:
《用无监督学习提高语言理解能力》(Improving Language Understanding with Unsupervised Learning)
《Transformer-XL:超出固定长度上下文的注意力语言模型》(Universal Language Model Fine-tuning for Text Classification)
BERT 框架是 Google AI 的一个新的语言表示模型,它使用预训练和微调来为各种任务创建最先进的模型。这些任务包括问答系统、情感分析和语言推理等。
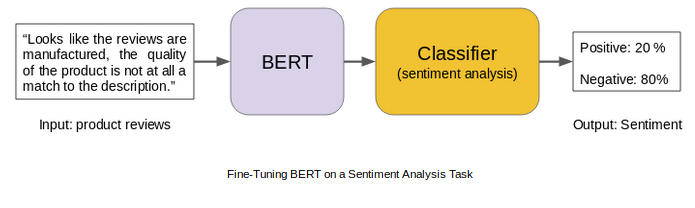
BERT 的模型架构
BERT 使用多层双向 Transformer 编码器。它的自注意力层在两个方向上都执行自注意力。Google 发布了该模型的两种变体:
BERT Base: Transformers 层数 = 12, 总参数 = 110M
BERT Large: Transformers 层数 = 24, 总参数 = 340M
BERT 使用使用双向性,通过对几个任务的预训练,掩码语言模型(Masked Language Model)和下一句的预测。让我们详细讨论这两个任务。
BERT 预训练任务
BERT 使用以下两个无监督预测任务对 BERT 进行预训练。
1. 掩码语言建模(Masked Language Modeling,MLM)
根据这篇论文:
“掩码语言建模从输入中随机掩盖一些标记,其目标是仅基于上下文预测被掩盖的单词的原始词汇 id。与从左到右的语言模型预训练不同,MLM 目标允许表示融合左和右上下文,这允许我们预训练深度双向 Transformer。”
Google AI 研究人员随机掩盖了每个序列中 15% 的单词。这个任务是什么?就是预测那些被掩盖的单词。此处需要注意的是,掩码单词并不总是被掩盖的标记 [MASK] [MASK] 标记在微调过程中永远不会出现。
因此,研究人员使用了以下技术:
有 80% 的单词被掩码标记 [MASK] 替换。
有 10% 的单词被随机单词替换。
有 10% 的单词保持不变。
2. 下一句的预测
一般来说,语言模型并不能捕捉连续句子之间的关系。BERT 也接受过这项任务的预训练。
对于语言模型的预训练,BERT 使用成对的句子作为训练数据。每对句子的选择非常有趣。让我们试着通过一个例子来理解它。
假设我们有一个包含 100000 条句子的文本数据集,我们想使用这个数据集来预训练 BERT 语言模型。因此,将有 50000 个训练样本或句子对作为训练数据。
对于 50% 的句子对来说,第二条句子实际上是第一条句子的下一条句子。
对于其余 50% 的句子对,第二条句子将是语料库中的一条随机句子。
对于第一种情况,标签是“IsNext”,第二种情况标签是“NotNext”。
像 BERT 这样的架构表明了,无监督学习(预训练和微调)将成为许多语言理解系统中的关键元素。资源较少的任务尤其可以从这些深度双向架构中获得巨大的好处。
如下图所示,是一些自然语言处理任务的快照,在这些任务重,BERT 扮演着重要角色:
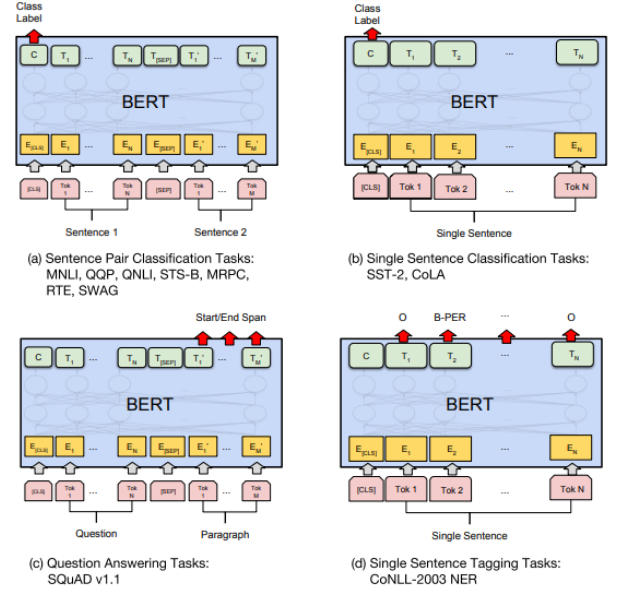
(来源:Source: https://arxiv.org/abs/1810.04805)
结 语
我们真的应该为自己感到幸运。因为自然语言处理技术以如此快的速度取得了最先进的进展。像 Transformer 和 BERT 这样的架构,正在为未来几年更先进的突破铺平了道路。
我鼓励你们去实现这些模型,你也可以参加以下的课程来学习或者提高你的自然语言处理方面的技能:
《使用 Python 的自然语言处理》(Natural Language Processing (NLP) using Python)
作者介绍
Prateek Joshi,数据科学家,就职于 Analytics Vidhya。在 BFSI 领域拥有多学科的学术背景和经验。
Transformer 的优势
并行处理能力
与传统的循环神经网络(RNN)和长短期记忆网络(LSTM)不同,Transformer 完全依赖于自注意力机制,消除了序列处理中的递归结构,允许模型在处理输入数据时实现高效的并行计算。这使得训练过程大大加速,特别是在使用现代 GPU 和 TPU 等硬件时。你可以回顾一下 Position Encoding 的作用,就是为序列添加位置编码,以便在并行处理完以后,进行合并。
捕捉长距离依赖
Transformer 通过自注意力机制能够捕捉序列中的长距离依赖关系。在自然语言处理中,这意味着模型可以有效地关联文本中相隔很远的词汇,提高对上下文的理解。灵活的注意力分布多头注意力机制允许 Transformer 在同一个模型中同时学习数据的不同表示。每个头可以专注于序列的不同方面,例如一个头关注语法结构,另一个头关注语义内容。
可扩展性
Transformer 模型可以很容易地扩展到非常大的数据集和非常深的网络结构。这一特性是通过模型的简单可堆叠的架构实现的,使其在训练非常大的模型时表现出色。
当然还有其他特性,比如适用性、通用性等,总的来说,Transformer 通过其独特的架构设计在效率、效果和灵活性方面提供了显著的优势,使其成为处理复杂序列数据任务的强大工具。
评论