
ChatGPT为什么崛起
NLP技术突破: 强势整合技术资源
基于Transformer架构的语言模型大体上分为2类, 一类是以BERT为代表的掩码语言模型(Masked Language Model, MLM), 一类以GPT为代表的自回归语言模型(Autoregressive Language Model, ALM).
按照人类语言的习惯, 语言本身就有先后顺序, 而且我们日常说话也是下文依赖上文.所以有人猜测, 自回归语言模型代表了标准语言模型, 利用上文信息预测下文, 这比传统AI预测更加复杂, 但是上限更高, 有望通向AGI, 这正是OpenAI的愿景.
基于自回归的无监督训练
无监督自回归的训练方式, 使GPT可以接受大量文本数据, 所以后来有了GPT3, 1750亿参数规模, 问鼎当时最大的模型.但此时还不具备和人类对话的能力.
RLHF
GPT3到GPT3.5再到ChatGPT, 参数规模并没有太大变化, 主要是有些技术微调, 适配人类场景, 这主要依赖RLHF(Reinforcement Learning From Humen Feedback, 人类反馈强化训练)
超大规模预训练
ChatGPT在技术上的突破可以理解为:
自回归语言模型+充分无监督训练+大量代码训练+有监督指令微调+RLHF
最后通过超大规模预训练变成无敌的存在.
提示工程
什么是提示
使用大模型时, 先给出提示, 大模型会根据提示来推测补全内容.实际上是根据训练过的记忆, 一个字一个字地计算概率, 取概率最大的那个字进行输出.
什么是提示工程
探讨如何设计出最佳提示, 用于指导语言模型帮助我们高效完成某项任务
如果AI大模型是你的员工, 他能否表现优秀, 除了他自身的潜质外, 还需要能够领导好他, 也就是我们常说的领导力, 在这里叫做AI领导力.
提示是我们和AI大模型沟通的唯一桥梁, 只有熟练掌握提示技巧, 才能进一步提升领导力, 进而让你轻松驾驭AI大模型
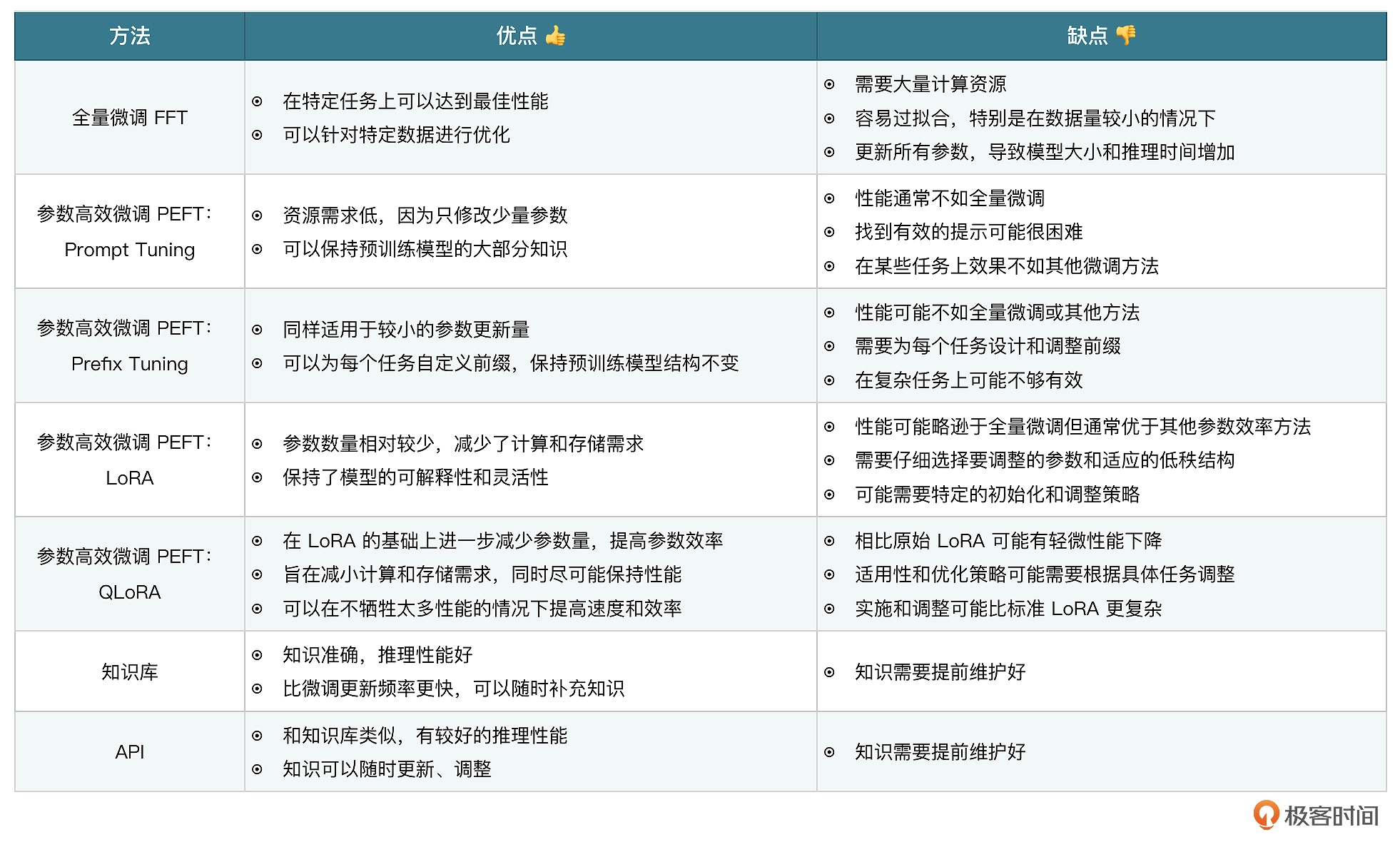
大模型微调
如何增强模型能力
微调是一种让预先训练好的模型适应特定任务或数据集的方案, 成本相对较低, 这种情况下, 模型会学习训练者提供的微调数据, 并且具备一定的理解能力
知识库: 使用向量数据库或其他数据库存储数据, 为大语言模型提供信息来源外挂
API和知识库类似, 为大语言模型提供信息来源外挂
FAQ
模型是不是越大越好?
不是, 有些参数量更大的模型性能不好, 没有经过充分训练
评论